MatHem is growing quickly and so are the requirements for fast and reliable data pipelines. Since I joined the company a little more than one year ago I’ve been developing an event streaming platform (named DataHem) to meet those requirements.
1 Background
Before jumping into the solution architecture, I thought I would give you some background from a business perspective that has influenced the design choices.
1.1 Context
MatHem is the biggest online grocery store in Sweden and to briefly give a context this is how the business works:
-
A customer orders groceries online in one of our digital channels (we have no physical stores).
-
The order is picked in one of our 3 warehouses located in the 3 biggest cities in Sweden, covering 65% of the Swedish population.
-
The groceries are loaded in one of our 200 cars (or 3 boats) and delivered to the customer (even to your jetty if you’re in the Stockholm archipelago)
Data is generated and collected in all of these steps as well as in the areas of supply, pricing, product assortment, content production, etc. Hence, data is embraced as a first-class citizen at MatHem and critical to generate advantages in a competitive market.
1.2 Requirements
The major business requirements on DataHem are:
-
Scalability and flexibility - Our quickly growing business also means our data platform needs to keep up with not only the ever-growing volumes of data but also the number of data sources and increasing complexity of our systems.
-
No-ops and synergies - the data engineering team is small and we need to make sure that our time is efficiently used and adding new data sources requires a minimum of work to set up and maintain. We also strive for synergies by collecting data once and use it for multiple purposes (reports, dashboards, analytics, machine learning and data products).
-
Data quality and resilience - make sure that reports and data products down-stream don’t break when the upstream data model evolves.
-
Availability and security - users should be able to easily interact with data with their tool of choice while ensuring fine grade access control on field level.
-
Full control and ownership of data - backfill and delete individual data records
2. Solution
In order to meet the requirements we’ve built DataHem, a serverless real-time end-2-end data pipeline built entirely on GoogleCloud Platform services. A major design goal has been to treat data as streams of immutable data objects (log) and publish the objects (orders, products, members, car temperatures, etc.) when they are created, modified or deleted. The data pipelines apply strong contracts early in the process by using protobuf. The central pieces of the solution are the protobuf schemas that contains meta data (options) and the generic dataflow/beam pipeline that use the meta data to process each message type accordingly.
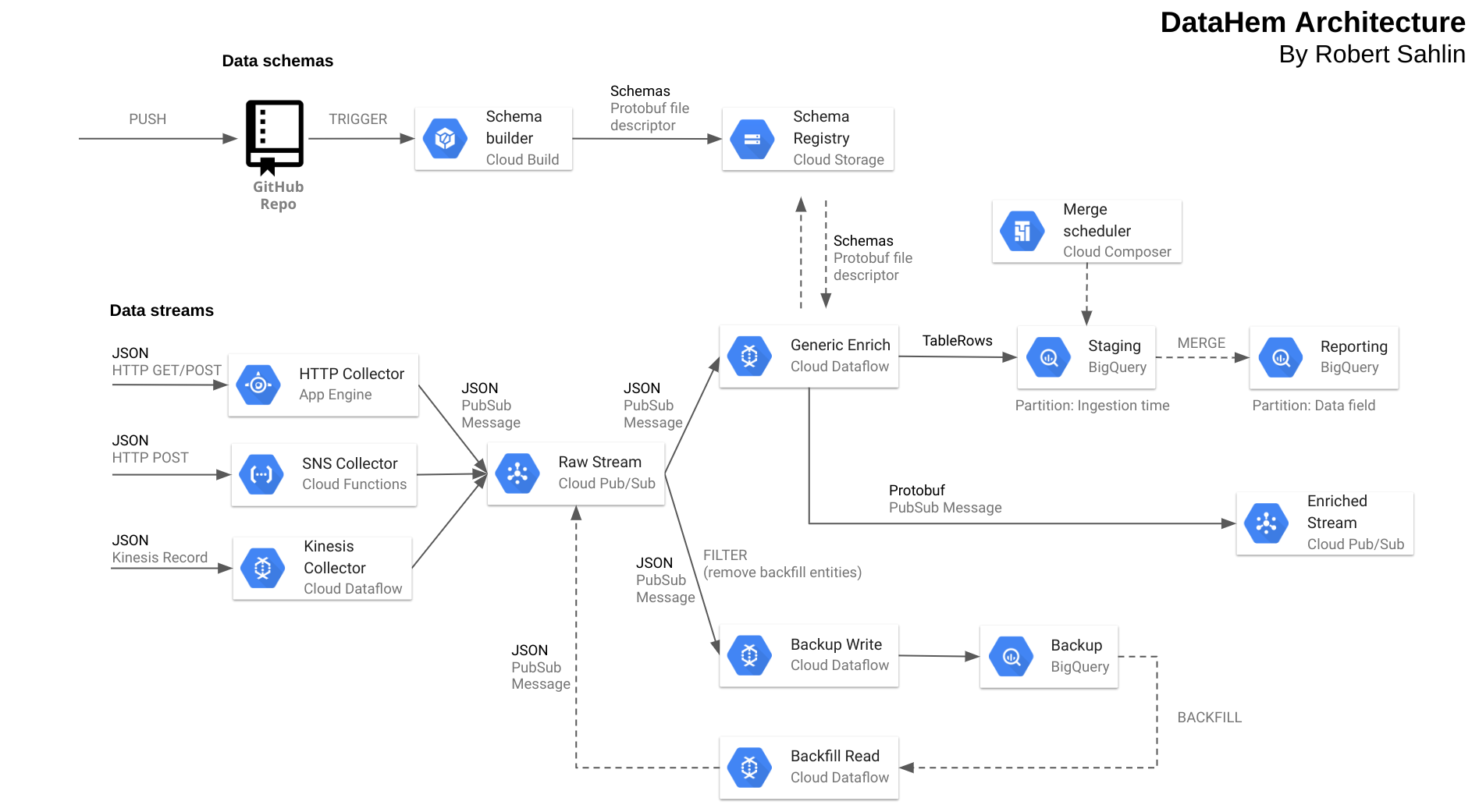
Let’s go through the different parts of the solution in detail.
2.1 Data sources
Understanding the source of the data is fundamental. At MatHem, most business related data is produced by our IT development teams. Their data is extensively used by the Data Science team to discover business insights and to build data products that better serve our customers. Most of MatHem’s frontend and backend is built on micro-services and runs on AWS and the developers use AWS SNS and Kinesis as their prefered message channels. These channels are some of the the most important data sources for us. We also have various clients (mobile apps & web) and third party services (webhooks) generating events data that are collected in realtime. However, the incoming data is in JSON format and we want strong contracts early on. Hence, we transform the JSON to protobuf that is available in many programming languages, has efficient serialization and supports schema evolution. All data objects also get meta data such as source, UUID and a timestamp as attributes.
To summarize, the following data sources need to be supported:
-
HTTP Requests (GET/POST)
-
AWS SNS
-
AWS Kinesis
2.2 Data collection
We use different GCP services as data collectors, all of them publish the JSON payload and meta data as pubsub messages. Each message type has its own pubsub topic and each topic has two subscriptions, one for backup and one for enrichment.
2.2.1 AWS Kinesis collector
For high volume streams from AWS we use dataflow/Apache Beam to read from AWS Kinesis. AWS user and secret are encrypted in GCP KMS to avoid accidental exposure of credentials.
2.2.2 AWS SNS HTTP Subscriber collector
For lower volume and small bursts of data from AWS we use cloud functions to read data from AWS SNS. The cloud function collector routes the incoming messages based on a query parameter, hence we can reuse the same cloud function endpoint for many HTTP SNS subscriptions and minimize operations.
2.2.3 HTTP collector
For data that is collected as HTTP GET or POST requests we use AppEngine standard. Our HTTP collector enable us to collect data from user interactions on our web application (we send all Google Analytics hits to our HTTP collector) and from third party service webhooks (like survey monkey forms).
2.3 Data processing
We use dataflow to process streaming data from pubsub and write to BigQuery in streaming mode. Many of the data objects are processed in a similar way, it’s just the schema that differs. Hence we’ve built a generic dataflow pipeline and specify processing logic in protobuf schemas using message and field options.
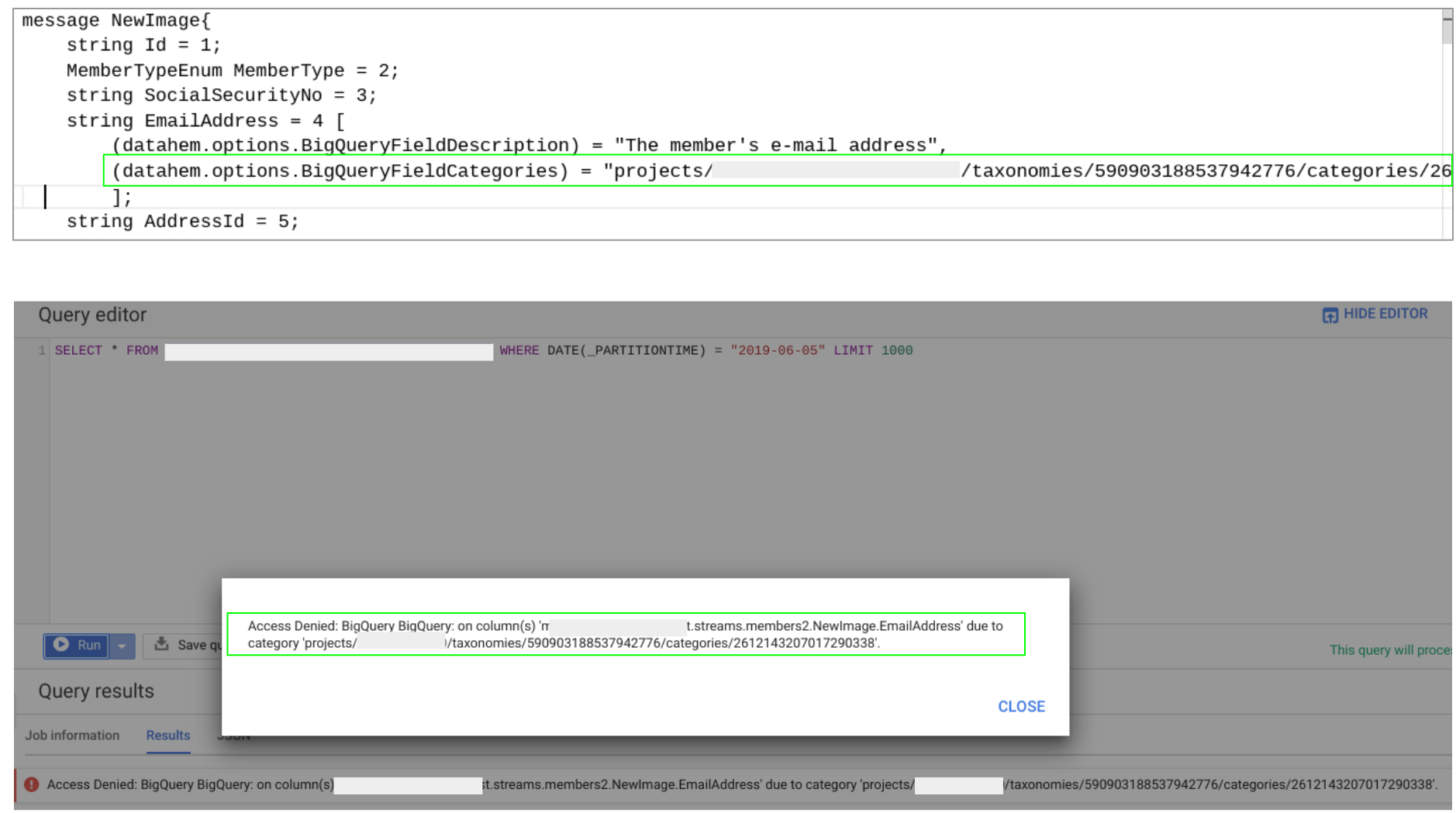
To illustrate that by example. One of our field level options is used to define BigQuery field categories. Categories is a part of the GCP Data Catalog service (Beta) that provides a foundation for data governance by defining taxonomies and connect that to column level ACL. This allow us to set access control already in the schemas. Dataflow picks up the schema from a schema registry and creates the corresponding BigQuery table (if it not already exists) before writing data to it. The schema registry is basically a protobuf descriptor file hosted in cloud storage and built with google cloud build and triggered by schema updates in our GitHub repository. Hence, adding a new data source and streaming data to a BigQuery table with the correct field level access control is done by pushing a protobuf schema to our GitHub repo. In a similar manner we also use protobuf options to add BigQuery column descriptions, BigQuery table descriptions and more.
Since we want to be able to use the same generic Beam pipline to process different message types we use protobuf dynamic messages rather than the corresponding java classes, hence the schema registry and no need to recompile pipelines when adding new message types. The pipeline can even be packaged as a cloud build job executing a container image that runs a fat jar and pull that from google container registry.
Data is written in realtime (< 5 seconds delay) to the staging table that is partitioned by ingestion time. At a defined schedule we merge data into reporting tables clustered on fields that optimize query performance. The merge into reporting tables allows us to avoid duplicates in situations when there is a backfill either from our backup tables or if the backfill stems from the data source that is outside control of the data engineering team. Queries that require realtime data runs against views that use analytical functions over the staging table or a union of the staging table and the reporting table.
2.4 Data destinations
To satisfy our main use cases; reporting, adhoc/explorative analysis, visualizations and ML/Data products we write the processed data objects to our data warehouse (BigQuery) and as streams (PubSub). Authentication and authorization of users is done close to the data warehouse to allow users to use their tool of choice (if it supports BigQuery) for adhoc/explorative analysis. Different roles in the company have different permissions to data fields. Hence, we need to set permissions on field level but also descriptions of each field.
2.5 Data backup
All raw data is streamed to a BigQuery dataset using dataflow jobs. The backup data is partitioned by ingestion time and have meta data (source, UUID, timestamp, etc.) in an attributes map that makes it easy to locate unique rows without parsing the raw data field (BYTES[]). Then a backfill is just a dataflow batch job that accepts a SQL-query and publish the data on the pubsub to be consumed by the streaming processing job together with the current data. The backfill data includes a message attribute that informs that it is a backfill entity and hence is filtered out from being written to the backup table again.
3 Summary
This is an overview of DataHem’s architecture to meet MatHem’s requirements while taking the data engineering prerequisites in consideration.
If you’re a data engineer and find this post interesting, don’t hesitate to reach out knowing that we’ve open data engineer positions at MatHem.
Also, I would like to mention Alex van Boxel who generously has offered invaluable guidance in how to read options from dynamic protobuf messages. I recommend you to keep an eye on his work on metastore and protobeam. In fact, DataHem depends on some of Alex’s code (ProtoDescriptor) and some modifications of it (ProtoLanguageFileWriter) to parse protobuf dynamic message options.
Kudos also to my fellow data engineering colleague David Raimosson for being an excellent sounding board and supporting with data domain knowledge and awesome SQL optimizations.