In the previous post, I covered how we create or patch BigQuery tables without interrupting the real-time ingestion. This post will focus on how we update the dataflow (Apache Beam) job without interrupting the real-time ingestion.
3 Dataflow
Google Cloud Dataflow is a fully managed service for executing Apache Beam pipelines within the Google Cloud Platform ecosystem. Apache Beam is an open source unified programming model to define and execute data processing pipelines, including ETL, batch and stream (continuous) processing. I’ve been developing ETL-jobs and pipelines in Hadoop (Hive, Pig, MapReduce) and Spark and discovered Apache Beam 2 years ago and never looked back, Apache Beam is awesome!
3.1 Generic pipelines
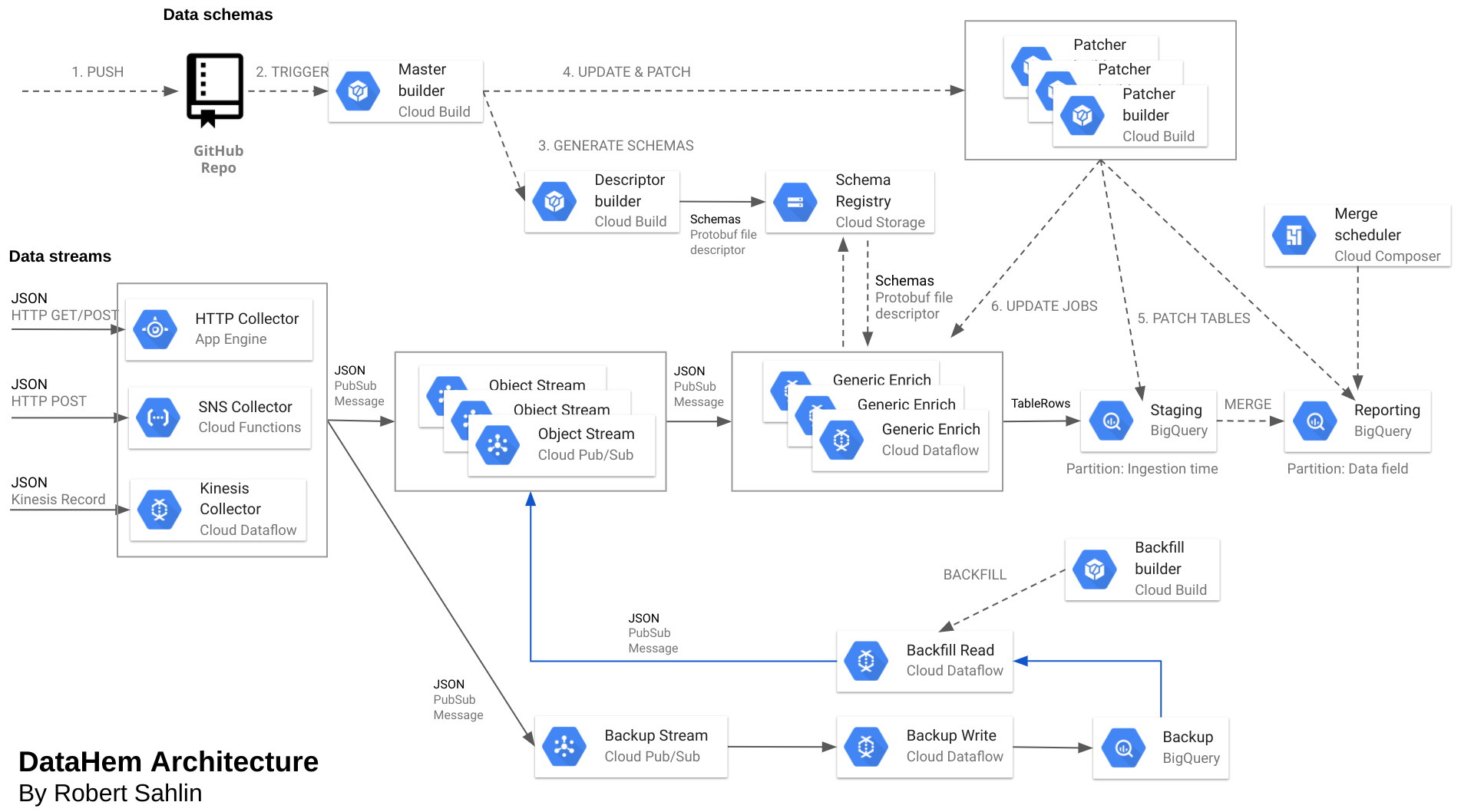
To avoid developing code for multiple data object pipelines that share 99% percent of the code (only the generated protobuf message class differs) we decided to develop a generic pipeline that can interpret messages dynamically based on a schema that is read at runtime rather than at compilation.
The pipeline accepts parameters such as what pubsub subscription to read messages from, where to find the file descriptor (our schema registry is a file descriptor in cloud storage), the full name of the message schema and what BigQuery table to write to. The pipeline is run in streaming mode and use small instances since it doesn’t do any aggregations. We set up one pipeline for each data object.
The generic pipeline parse JSON against the specified protobuf schema and alert if fields are missing (but still processing the record). The protobuf message is then transformed into a tablerow according to the message and field annotations in the schema.
The entities are written to a staging table in BigQuery that is partitioned on ingestion time, hence we can run backfills to the same pipeline without facing limitations in partitioning records older than 30 days. Every midnight we merge entities from the staging table into the reporting table that is partitioned on a field rather than ingestion time. Queries are run against a view that union the reporting table and last 2 days in the staging table, hence we get both query performance and real-time data while allowing for backfills in an easy way.
We have two very similar pipelines, one for reading entities from dynamoDB streams, publish JSON with NewImage and OldImage of each entity, and one generic for entities with only one version (Image) of each entity.
Dataflow jobs can easily be updated as long as the pipeline DAG doesn’t change, hence we can update streaming jobs when the schema is updated, without interuptions.
3.2 Docker image
The pipelines are run with Cloud Build, packaged as a fat jar in a docker image, rather than as dataflow templates with valueproviders. The reason is that it allows us to:
- use options wherever we want in our code
- use complex options (combine 2 or more)
- use dynamic DAGs based on provided options
The Docker-file is very simple.
FROM openjdk:8u212-jre-slim-stretch
COPY generic-pipeline-bundled.jar /target/
and the cloudbuild.yaml as well.
# gcloud builds submit --config=cloudbuild.yaml . --substitutions=TAG_NAME=0.7.3
steps:
- name: maven:3.6.2-jdk-8-slim
entrypoint: 'mvn'
args: ['package']
- name: gcr.io/cloud-builders/docker
args: ['build', '-t', 'gcr.io/$PROJECT_ID/generic-pipeline:$TAG_NAME', '.']
- name: gcr.io/cloud-builders/docker
args: ['build', '-t', 'gcr.io/$PROJECT_ID/generic-pipeline:latest', '.']
images: ['gcr.io/$PROJECT_ID/generic-pipeline']
Everytime we push code to github we trigger a build that generate the image we later use in the automation of schema evolution.
3.3 Update
Updating the dataflow job is just launching a job with the same name as the running job but set with the update flag.
3.3 Backup pipelines
In parallell with the generic pipelines we also have a backup pipeline that consumes messages from all topics and write the records to the same BigQuery table (partitioned on topic) as a data field (message as BYTES) together with message attributes and partitioned on ingestion time. Hence we can do a backfill at any point with a backfill pipeline that accepts a SQL-query and pubsub topic as parameters and point the output to the topic read by the generic pipeline for the specific topic, and will just scale up the workers during the backfill and go back to normal when done! I will publish a separate post on this.
In the next post (part 4) I will focus on the automation part using Google Cloud Build.