Data Build Tool (dbt) is an awesome open source tool founded by dbt labs that also offers a managed service to work with dbt. But you can also host dbt yourself and do that all serverless with a collaborative setup following GitOps practices, best of all - it is easy to set up and very cost efficient.
Managed service or self-hosted?
Before jumping onto the setup you should ask yourself what option suit you the best. A not complete list of arguments for one option over the other below:
dbt cloud
Great for teams that want to get started quickly
- I want to onboard a larger team in the quickest manner possible
- My team is skilled in SQL, but unfamiliar with git
- We need a support package
self-hosted
Great for teams that want greater customization and are willing to take on more infrastructure responsibilities
- I have access to resources skilled in moving and transforming data and maintain infrastructure
- I also have transformation logic that is hard to implement in SQL
- I want complete control of my data (not sharing access with third party)
- My team knows git and already have a favourite IDE
- I need high degree of concurrency of running jobs
- I want to control access with the same IAM/ACL as in GCP
- My team should be able to do everything in a single platform (GCP)
- I want to pay for resources we use (serverless), not developer seats.
- We need multiple environments (prod, dev, test, etc.)
Solution architecture
Ok, if you’ve decided for the self-hosted setup then this setup may be for you (if you’re on Google Cloud Platform that is). The setup contains the following components:
- Local installation of your favorite IDE (with dbt plugins), dbt and git
- Private Github repo where you store and collaborate on your models in the team
- Cloud Build to execute tests on Pull Requests and run scheduled executions
- BigQuery as data warehouse
- Cloud Scheduler to trigger runs on a schema
- Cloud Workflows for execution logic and modularity (optional)
- Cloud Monitoring to set up SLA:s and alerts (optional)
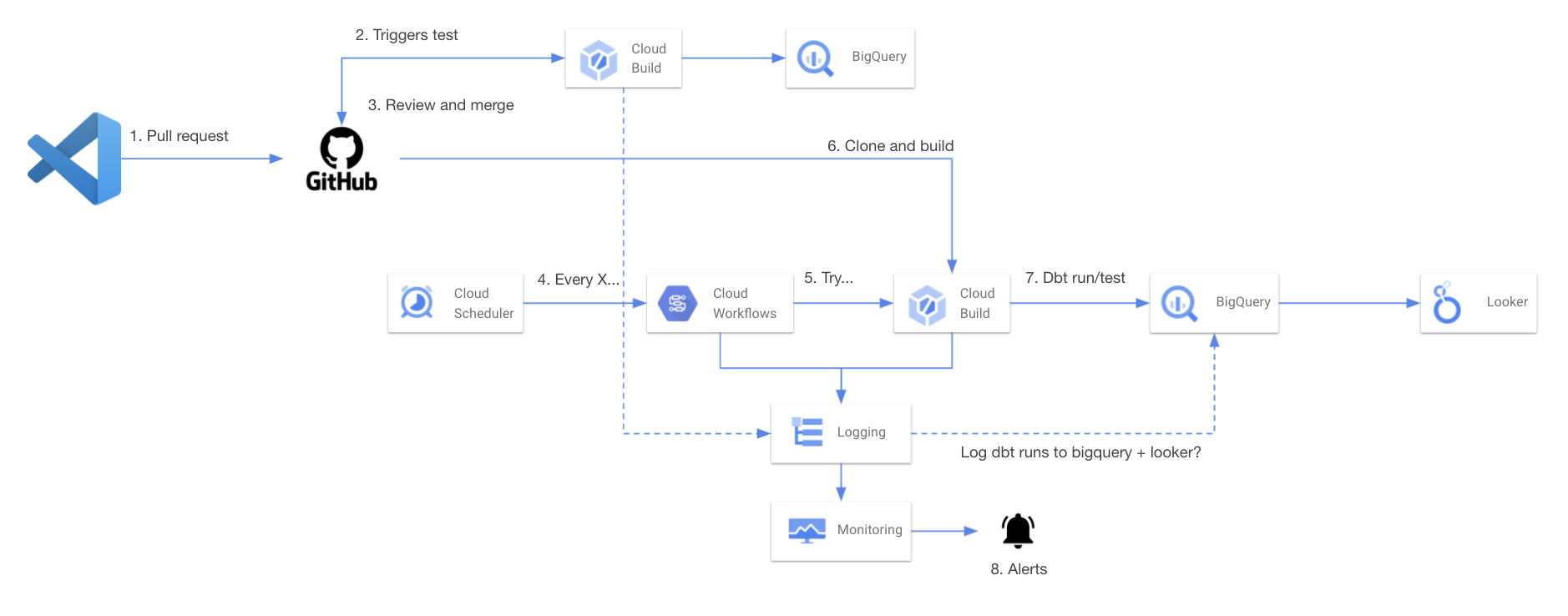
Brief overview (GitHub Flow):
- Develop locally and run dbt commands as usual with your local profile
- When you make a Pull Request to main/master branch a cloud build job is triggered to compile, run and test your code targeting your dev output profile.
- Team members review your code and your code is then merged into main/master branch
- Cloud build runs dbt (targeting prod output profile) on a schedule triggered either directly in cloud build or using scheduled workflow jobs that allow for customized retry logic and logging
- If the job fails, trigger an alert in cloud monitoring to notify you/team
- If you want, you can use the custom logs to send data to BigQuery and build custom reports/dashboards in Looker or Data Studio about you dbt runs, but that is the topic of another post
Step-by-step
Here are the steps needed to set up the solution. I will assume you already have a Github account and a GCP project with BigQuery as your data warehouse. I will also assume you have a local development environment with dbt, git and IDE.
Considerations
Regardless of the GCP project where you store your data, consider using different projects for hosting your dbt solution and the project used by analysts, the reasons are multiple:
- The quota for BigQuery Query Processed data per user and day will apply on all users in a project. The dbt project service account is likely to process more data than individual users and hence you may want to set different (lower) quota for users than the dbt service account.
- If users accumulate a lot of processed data in BigQuery, you may end up hitting the BigQuery project level quota for processed data, you don’t want that to have negative impact on your scheduled dbt jobs.
- If you have a lot of continuous and predictable processing done by dbt, then it may be worth having BigQuery reserved slots that you don’t want to be consumed by user queries.
1. GitHub
Create a GitHub repo and clone it into your local computer and create a feature-branch for the initialization (ex. “init” as in the code block below).
git clone https://github.com/YOUR-ORGNAME/YOUR-REPOSITORY
git checkout -b init
2. Cloud Build
We need to create 2 cloud build triggers, one pull request trigger running with dev as target and one scheduled trigger running with prod as target. Since are running dbt from cloud build we need to make sure that the cloud build service account (your_projectnumber@cloudbuild.gserviceaccount.com) has the roles BigQuery Data Editor and BigQuery User.
Pull Request trigger
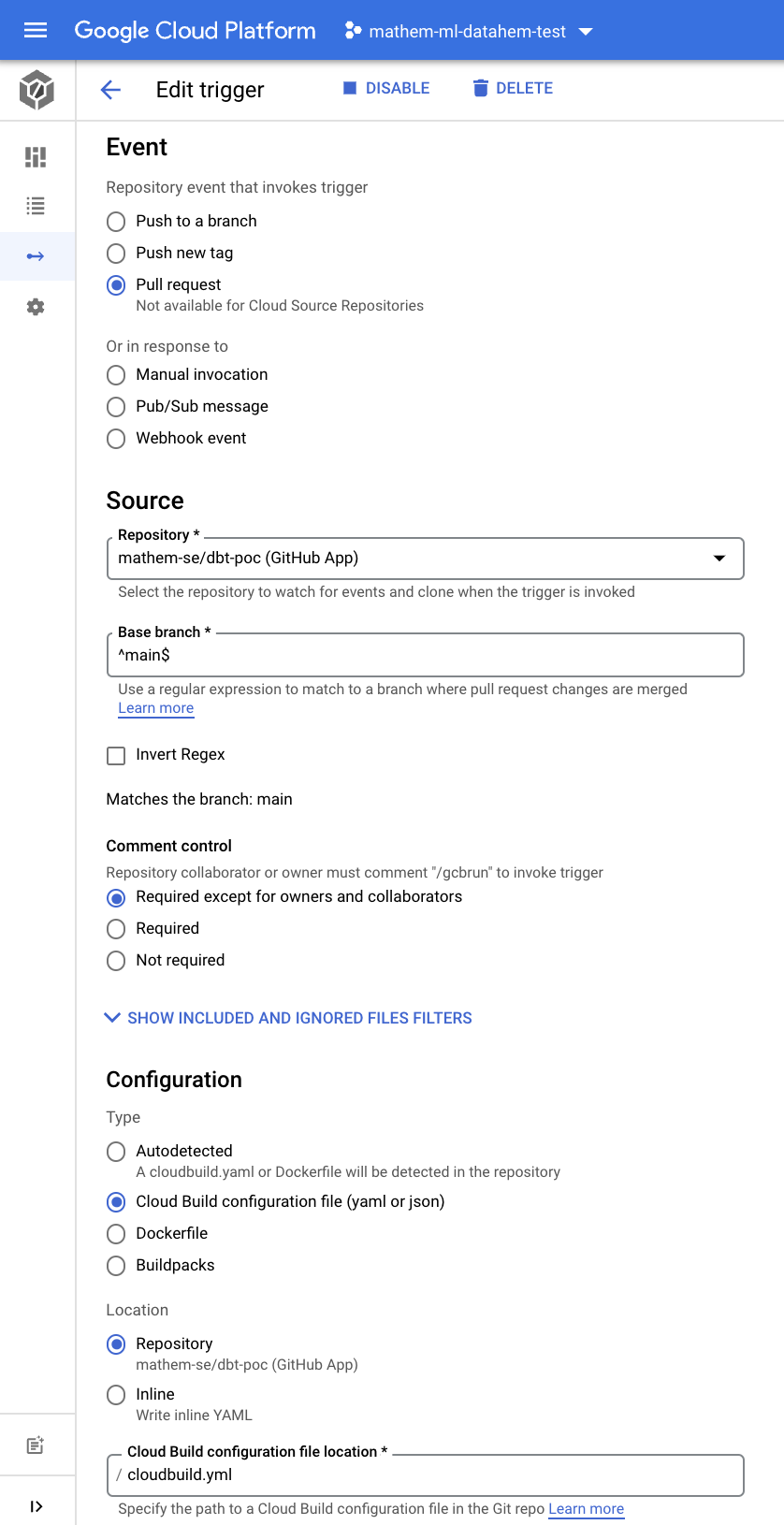
Create a trigger that you connect to your dbt github repo (Cloud Build GitHub App). Give it a name and description and make sure it is triggered by pull request and base branch is ^main$ and configuration is cloudbuild file and path is set to cloudbuild.yml.
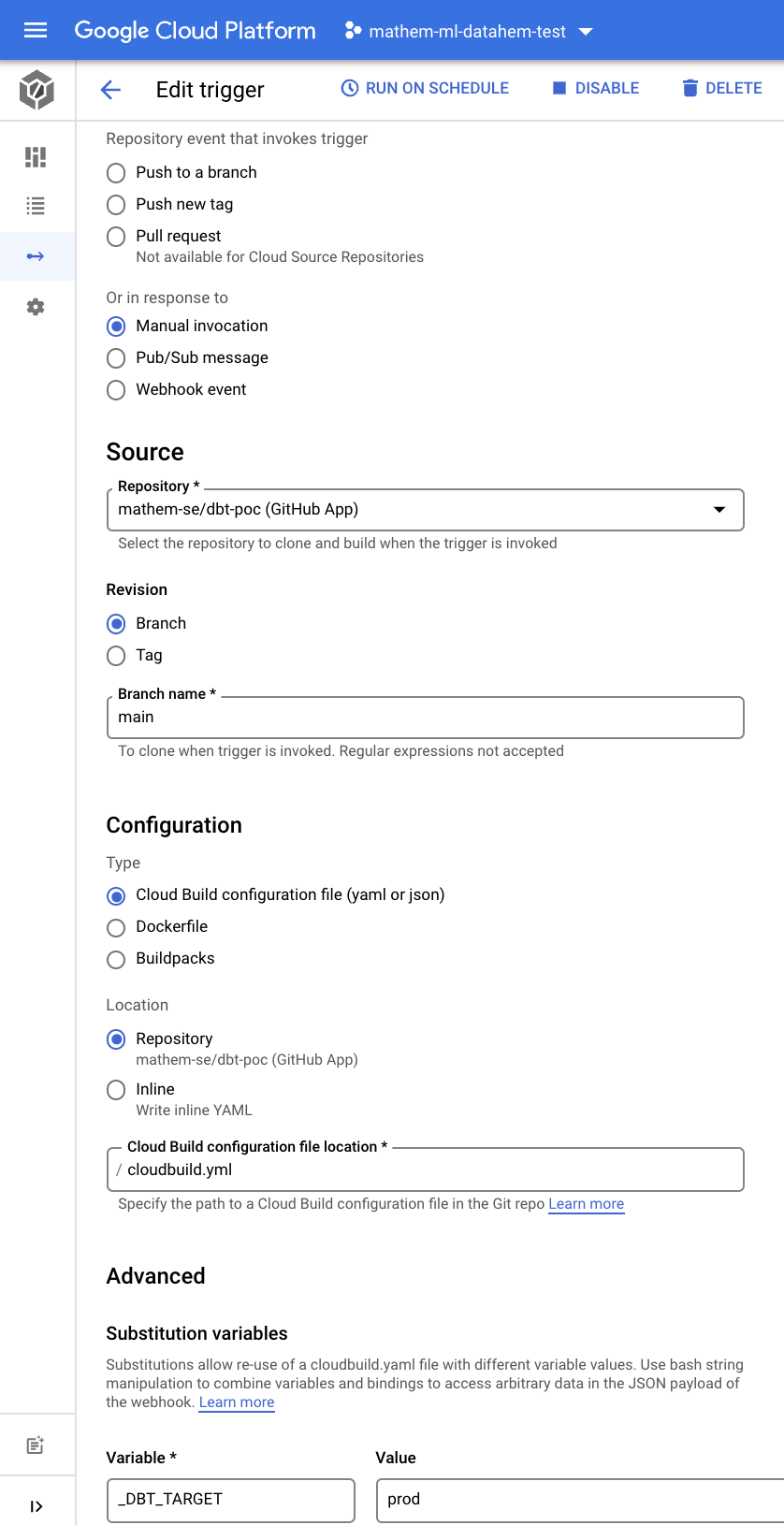
Scheduled trigger
Clone (copy) the PR trigger you just created. Modify the trigger to be manual invocation and branch set to ^main$ and create a substitution variable \_DBT_TARGET set to prod. One alternative to schedule the runs is to configure scheduled builds directly in cloud build. The other alternative (that I prefer) is to schedule a workflow that triggers the cloud build, that gives you better control of retries etc. and logging (see the workflows step below).
Initialize a dbt project
Create a dbt project (if you don’t already have one) and add a profiles.yml and a cloudbuild.yml in the folder and make sure your project (dbt_project.yml) name and models match with your folder structure and profiles name.
folder and files
Your dbt project structure should look something like this.
dbt-poc/
- analysis/
- data/
- logs/
- macros/
- models/
- snapshots/
- tests/
- dbt_project.yml
- packages.yml
- README.md
- profiles.yml
- cloudbuild.yml
profiles.yml
Since we will use the default cloud build service account we can use oauth both when running dbt locally and with cloud build.
dbt_poc: # your profile name from dbt_project.yml
target: dev # your development environment
outputs:
dev:
type: bigquery
method: oauth
project: my-gcp-dev-project # name of the project in BigQuery
dataset: dbt_poc_test # your dataset for development (usually your name)
threads: 4
timeout_seconds: 300
priority: interactive
retries: 1
prod: # your production environment
type: bigquery
method: oauth
project: my-gcp-prod-project # name of the project in BigQuery
dataset: dbt_poc_prod # your dataset for production
threads: 4
timeout_seconds: 300
priority: interactive
retries: 1
dbt_project.yml
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models
name: 'dbt_poc'
version: '1.0.0'
config-version: 2
# This setting configures which "profile" dbt uses for this project.
profile: 'dbt_poc'
# These configurations specify where dbt should look for different types of files.
# The `source-paths` config, for example, states that models in this project can be
# found in the "models/" directory. You probably won't need to change these!
source-paths: ["models"]
analysis-paths: ["analysis"]
test-paths: ["tests"]
data-paths: ["data"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
target-path: "target" # directory which will store compiled SQL files
clean-targets: # directories to be removed by `dbt clean`
- "target"
- "dbt_modules"
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build all models in the example/ directory
# as tables. These settings can be overridden in the individual model files
# using the `{{ config(...) }}` macro.
models:
dbt_poc:
# Config indicated by + and applies to all files under models/example/
example:
+materialized: view
cloudbuild.yml
The cloudbuild file reference the official dbt docker image, but you could store that image in artifact/container registry to avoid downloading from dockerhub each time. Updated (2021-12-17): After each step check if dbt returns exit code 1, if so exit build and report error.
# gcloud builds submit --config=cloudbuild.yaml .
steps:
- id: '1 Run dbt'
name: 'fishtownanalytics/dbt:${_DBT_VERSION}'
entrypoint: 'bash'
args:
- '-c'
- |-
dbt deps --profiles-dir .
if [[ $? == 1 ]]; then
echo '1'
exit 1
fi
dbt debug --target ${_DBT_TARGET} --profiles-dir .
if [[ $? == 1 ]]; then
echo '1'
exit 1
fi
dbt run --target ${_DBT_TARGET} --profiles-dir .
if [[ $? == 1 ]]; then
echo '1'
exit 1
fi
dbt test --data --target ${_DBT_TARGET} --profiles-dir .
if [[ $? == 1 ]]; then
echo '1'
exit 1
fi
timeout: 1200s
tags: ['dbt']
substitutions:
_DBT_VERSION: '0.21.0'
_DBT_TARGET: 'dev'
Trigger the PR trigger
Now it is time to push your changes in your feature branch (init in the example) branch to GitHub and create a pull request to the main branch. This will trigger the pull request trigger and run the dbt commands in the cloudbuild.yml with dev as target. Merge the code when/if the check pass and your team has approved your pull request. Now you have validated code in the main branch that is used by the trigger used for scheduled dbt jobs.
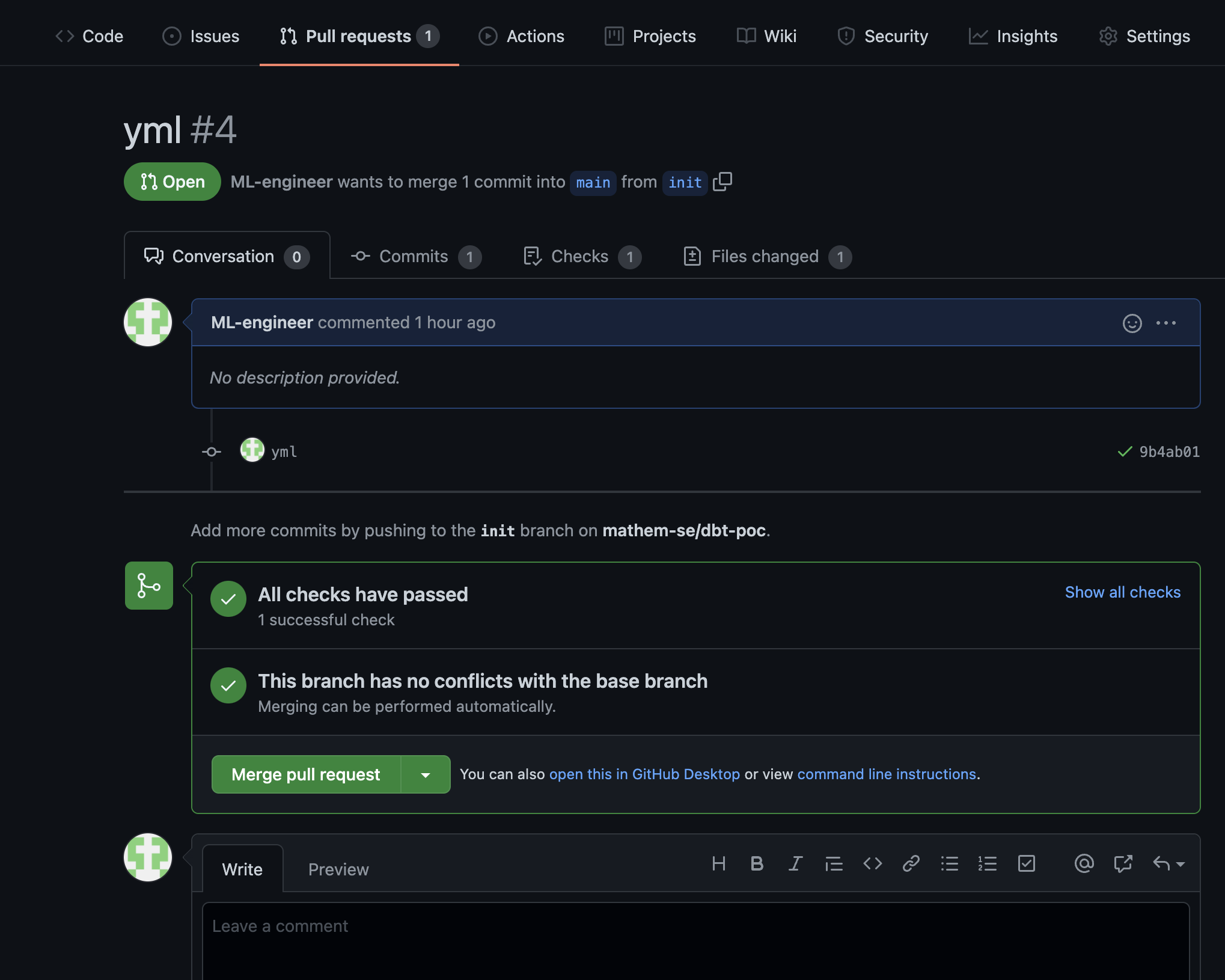
Workflows
First create a service account (ex. scheduler-workflows-invoker) with the Workflows Invoker role, you need it to set up the scheduled trigger. Now it is time to create a scheduled workflow that trigger the cloud build trigger. The first step is straight forward, create a trigger without any special arguments, a cron frequency (ex. 0 * * * * for every hour) and the scheduler-workflows-invoker service account. In the second step you define the workflow as below, make sure to replace the trigger id with your own triggerId, you find it in the url when you click on your cloud build trigger (I haven’t found out a better way to do that in the console).
I will evolve this workflow with retry logic and runtime parameters to be able to use the same workflow but with different triggers with different frequencies and execution tags to be able to run different models at different frequencies, but that is the subject for the next post.
For now, use the definiton below.
- init:
assign:
- project_id: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
- trigger_id: "e46d5333-7d56-46b0-9372-d67ee9dfdadc" # change this to your cloud build trigger id
- create_build:
call: googleapis.cloudbuild.v1.projects.triggers.run
args:
projectId: ${project_id}
triggerId: ${trigger_id}
result: response
- log:
call: sys.log
args:
data: ${response}
- the_end:
return: ${response}
Now you can try your new workflow by executing it manually from the console. It should trigger your scheduled cloud build trigger and execute the dbt commands with prod as target. You can control this in BigQuery.
Monitoring
You can monitor your jobs in your cloud build dashboard and in workflows dashboard.
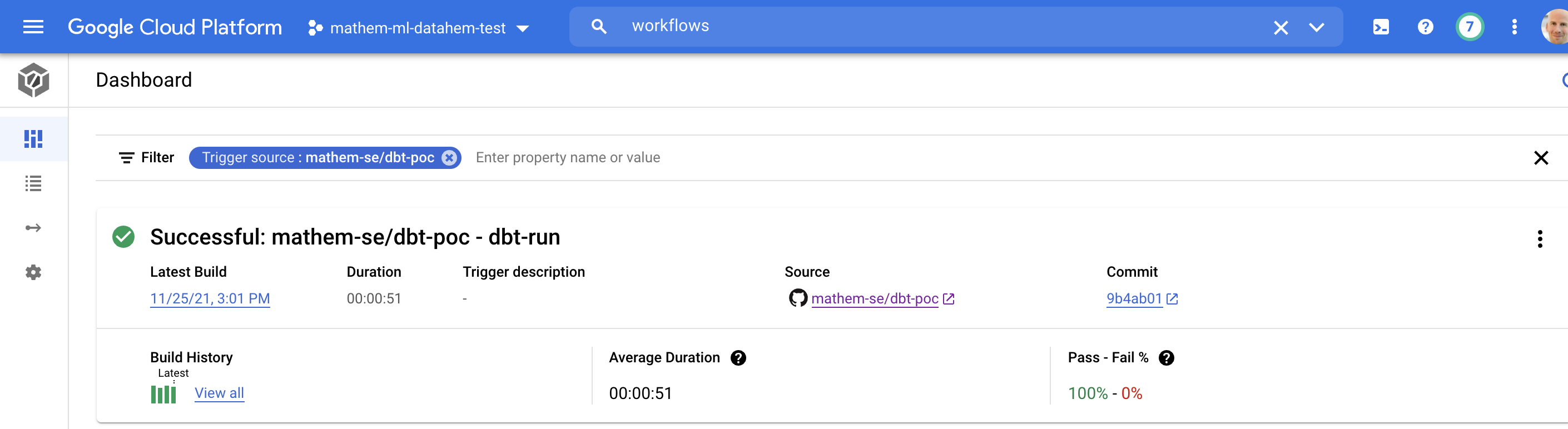
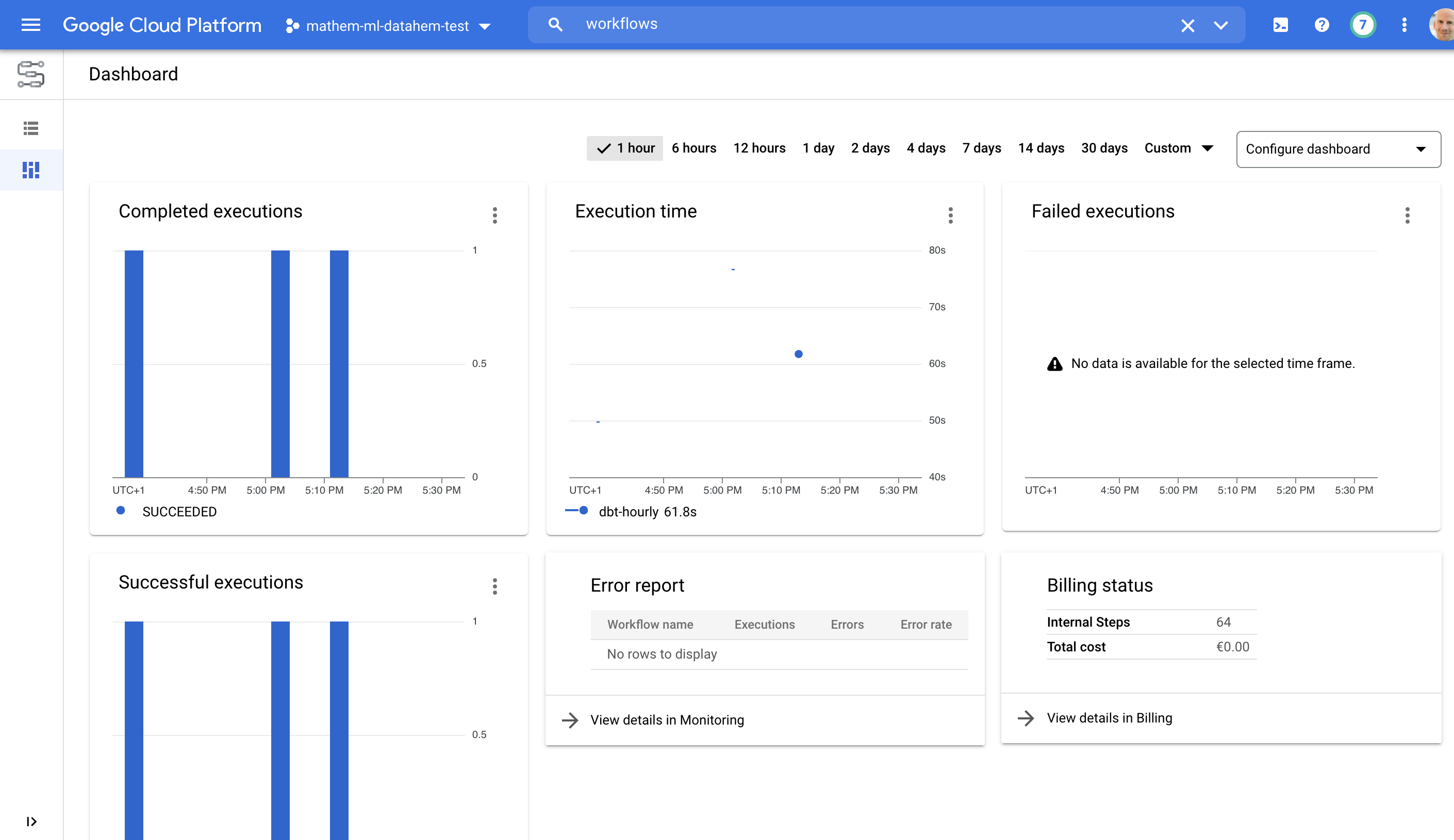
I will write a separate post on how to setup policies, alerts and SLA:s.
Summary
You should now have a serverless solution to run dbt in a self-hosted and collaborative setup and being able to follow GitOps style. I will write more posts on how to evolve this solution to fit different needs and use cases. Please comment or share if you find this post helpful.