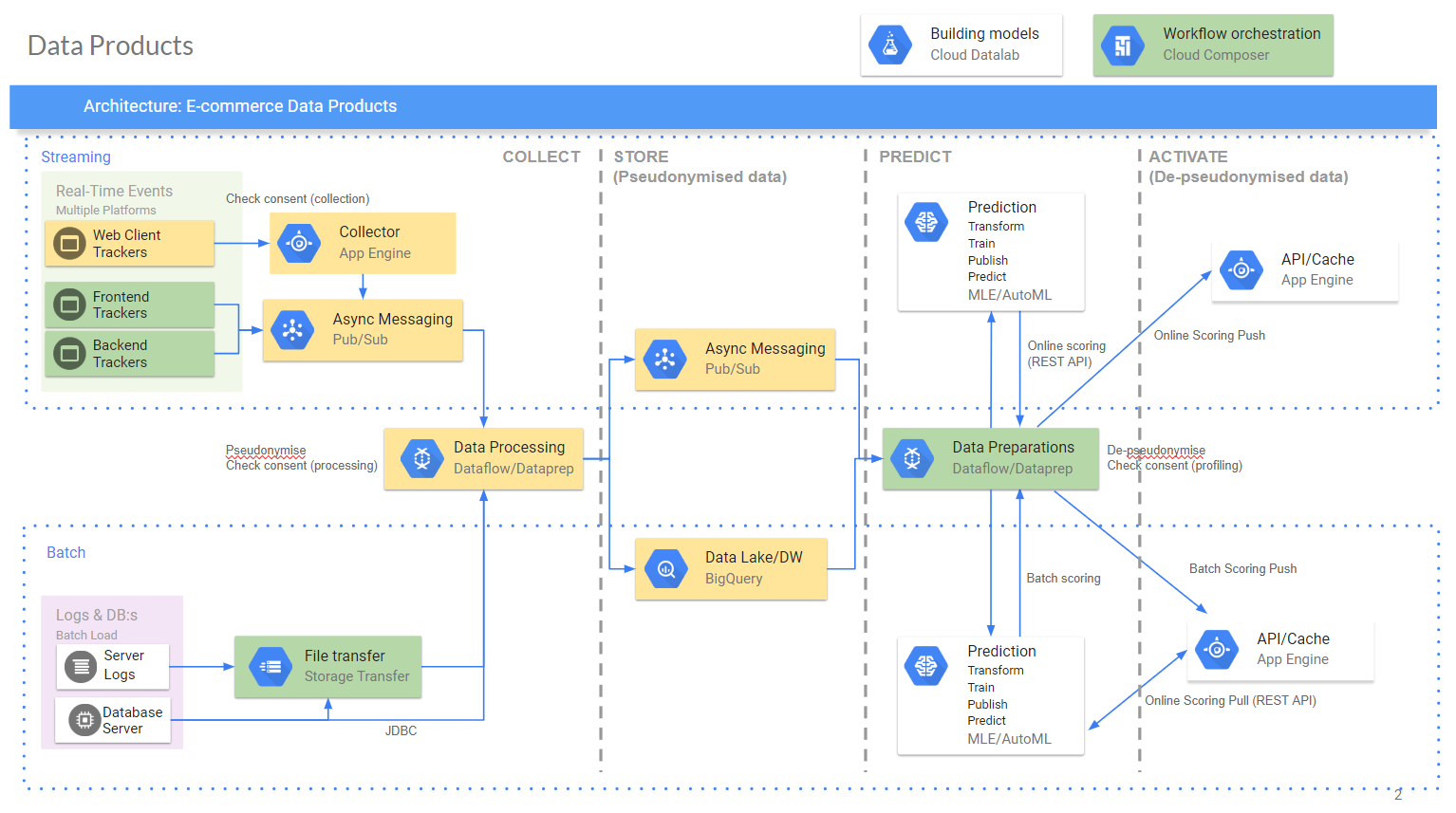
I’m excited to say that the project I’ve been working on the last year is now released as OpenSource (MIT license). DataHem is a serverless real-time end-2-end ML pipeline built entirely on GoogleCloud Platform services - AppEngine, PubSub, Dataflow, BigQuery, Cloud ML Engine, Deployment Manager, Cloud Build and Cloud Composer.
When building ML/Data products, your most valuable asset is your data. Hence, the purpose of DataHem is to give you:
- Full control and ownership of your data and data platform
- Unsampled data
- Data in real time
- The ability to replay/reprocess your data unlimited times
- Data synergies, i.e. collect once and use for multiple purposes (reporting, analytics and building data/ML products)
- Low cost of operations and maintenance
- Scalability
- Data as a stream and at rest
- Activation of data
- Ability to delete data on a row by row basis
It started of as a hobby project on my spare time, but since joining MatHem.se I’ve been given the possibility to develop and implement DataHem as part of my work, hence the naming is dedicated to my employer that has been supportive and encouraging.
One common usecase is to supercharge your Google Analytics implementation and use all the premium benefits mentioned above in reporting, analytics and activation of data that you’ve already tagged in GA, best of all - you only pay for storage and compute in GCP, no license fees.
The target architecture looks like this: