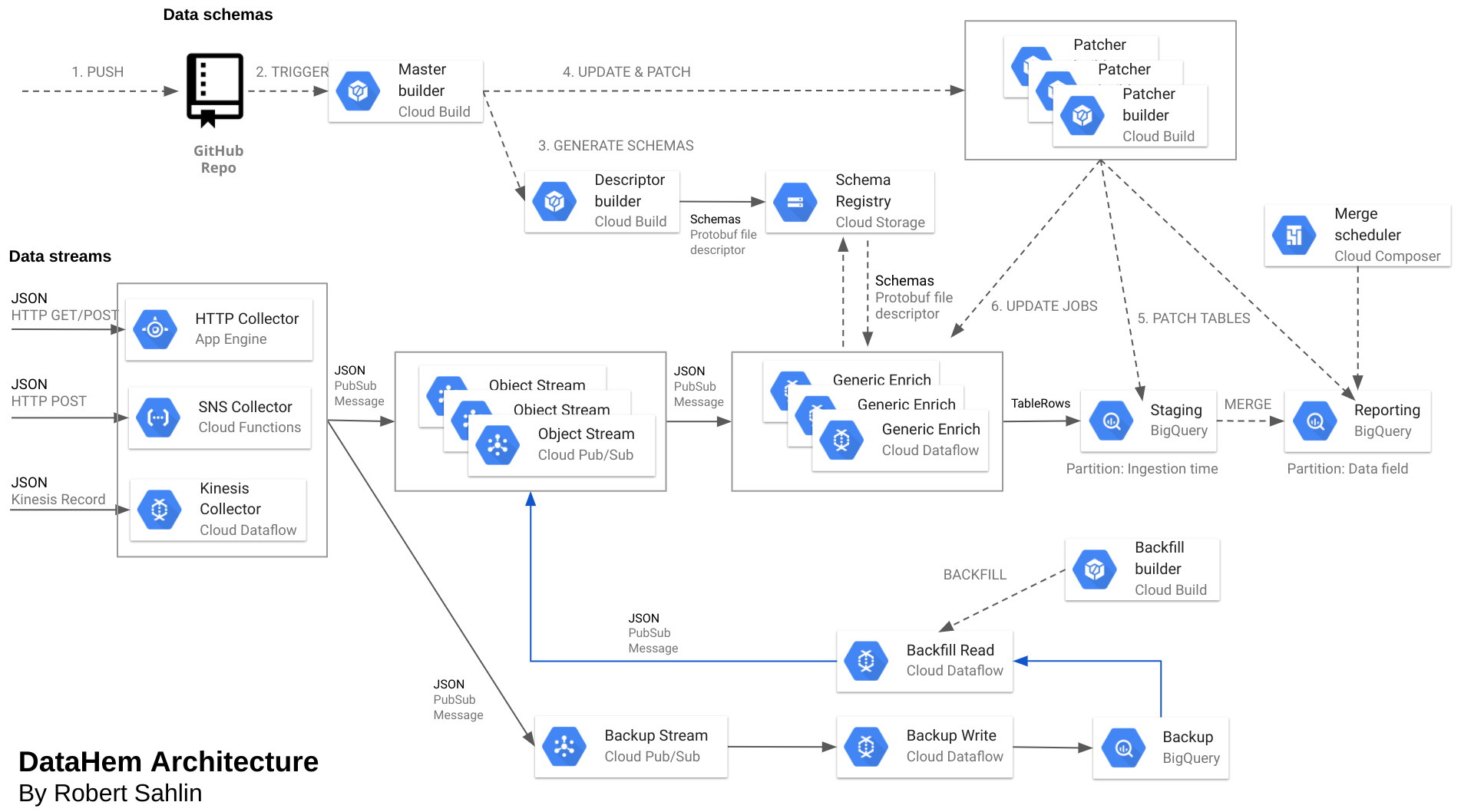
In the previous post, I gave an overview of MatHem’s streaming analytics platform DataHem. This post will focus on how we manage schema evolution without sacrificing real-time data or having downtime in our data ingestion.
The streaming analytics platform is built entirely on Google Cloud Platform and use services such as Dataflow, BigQuery and PubSub extensively. Another important component are protobuf schemas.
1 Protocol buffers
There are many different frameworks for serialization/deserialization of data. We actually started with Avro and even built custom JSON parser and a GCP Datastore schema registry before we decided that protocol buffers suited us better. Protocol buffers is a flexible, efficient way of serializing structured data. You define how you want your data to be structured in a schema file (.proto), then you generate source code in a variety of supported languages to easily write and read your structured data (messages) to and from a variety of data streams. You can even update your data structure without breaking deployed programs that are compiled against the “old” format.
Why do we want protocol buffers to start with? The reasons are primarily two:
- Most of the incoming data is in JSON format which is easy to read for humans but has multiple drawbacks when building an analytics platform. Protobuf schemas let us apply contracts early in the processing of entities and ensures that downstream consumers don’t break when the schema evolves. The rules for schema evolution in protobuf are similar to the ones in BigQuery (except for field removal or renaming fields).
- The schema allows us to annotate processing logic on both message and field level that enable us to build more generic processing pipelines that can be reused for multiple data objects. This is facilitated by the use of protobuf dynamic messages.
1.1 Proto files
Our data objects are described in proto files. Below is a simple example of how we represent truck temperatures that are streamed from a microservice in AWS. As an online grocery store, keeping track on the temperatures in our trucks is very important. The JSON-object we receive in our cloud functions collector looks like below and is published on two pubsub topics, backup and tms-truck-temperatures, together with som message attributes (meta-data).
{
"Temperature":3.0,
"Car":"D53",
"Timestamp":"2019-11-11 13:13:52"
}
But most of our data objects (orders, members, products, etc.) are more complex and contain more than 100 fields in nested and repeated structures. The corresponding protobuf schema looks like:
syntax = "proto3";
package mathem.distribution.tms_truck_temperature.truck_temperature.v1;
import "datahem/options/options.proto";
option java_multiple_files = true;
option java_package = "se.mathem.protobuf.tms.truck.temperature.v1";
message TruckTemperature {
option (datahem.options.BigQueryTableDescription) = "Truck temperatures from AWS";
double Temperature = 1 [
(datahem.options.BigQueryFieldDescription) = "Truck temperature in celsius",
(datahem.options.BigQueryFieldUseDefaultValue) = "false"
];
string Car = 2 [
(datahem.options.BigQueryFieldDescription) = "Truck ID/name"
];
string Timestamp = 3 [
(datahem.options.BigQueryFieldDescription) = "Timestamp (UTC) for when the temperature was logged.",
(datahem.options.BigQueryFieldType) = "TIMESTAMP"
];
map<string,string> _ATTRIBUTES = 300 [
(datahem.options.BigQueryFieldDescription) = "Message meta-data."
];
}
As you can see, data objects are structured according to domain/service/object and versioned with major (breaking change) version semantics. The message has one option and four fields; Temperature, Car, Timestamp and ATTRIBUTES. The ATTRIBUTTES field is a map that contains message meta-data, such as uuid, topic, timestamp etc. that is useful for example backfills or deleting individual rows.
The folder structure is like this:
proto/
--datahem/
----options/
------options.proto
--mathem/
----distribution/
------tms_truck_temperature/
--------truck_temperature/
----------v1/
------------truck_temperature.proto
----commerce/
----warehouse/
...
1.2 Schema options
The protobuf schema also support options that we can use to annotate processing logic both on field level and message level. DataHem is defined in protobuf and currently support the following options:
syntax = "proto3";
package datahem.options;
import "google/protobuf/descriptor.proto";
option java_package = "org.datahem.protobuf.options";
extend google.protobuf.MessageOptions {
string BigQueryTableReference = 66666667;
string BigQueryTableDescription = 66666668;
}
extend google.protobuf.FieldOptions {
// [DescriptionString] Example: "A timestamp."
string BigQueryFieldDescription = 66666667;
// [PolicyTag1, PolicyTag2,...] Example:
string BigQueryFieldCategories = 66666668;
// [BigQueryDataType] Example: "TIMESTAMP"
string BigQueryFieldType = 66666669;
// [NewFieldName] Example: "LocalDateTime"
string BigQueryFieldRename = 66666670;
// [AppendString] Example: "Europe/Stockholm"
string BigQueryFieldAppend = 66666671;
// [RegexPattern] Example "[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[1-2][0-9]|3[0-1])(T| )(2[0-3]|[01][0-9]):[0-5][0-9]:[0-5][0-9]"
string BigQueryFieldRegexExtract = 66666672;
// [RegexPattern, ReplacementString] Example: "(\\+(2[0-3]|[01][0-9]):[0-5][0-9]),Europe/Stockholm"
string BigQueryFieldRegexReplace = 66666673;
// [LocalTimezone, LocalPattern, UtcPattern ] Example: "Europe/Stockholm, yyyy-MM-dd'T'HH:mm:ss, yyyy-MM-dd'T'HH:mm:ssXXX"
string BigQueryFieldLocalToUtc = 66666674;
//[Hidden] Example: "true"
string BigQueryFieldHidden = 66666675;
//[Hidden] Example: "false"
string BigQueryFieldUseDefaultValue = 66666676;
}
Many of the options are used for describing messages or fields, extracting/replacing parts of data from a field or transforming data into BigQuery’s time or date types.
1.3 Dynamic messages
Protobuf schemas can be used to either generate message classes in various programming languages or a descriptor file that can be used to serialize/deserialize dynamic messages. We primarily use dynamic messages since it allows us to process various data objects using the same generic Dataflow (Apache Beam) pipelines together with the descriptor file stored in cloud storage (i.e. like a schema repository).
1.4 Generate descriptor file and upload to cloud storage
In order to generate a descriptor file or source classes you need to run the proto compiler (protoc). If you want to try it out locally, install it by running below (remember to change robert_sahlin to you own user).
wget https://github.com/protocolbuffers/protobuf/releases/download/v3.7.1/protoc-3.7.1-linux-x86_64.zip
unzip protoc-3.7.1-linux-x86_64.zip -d protoc3
sudo cp -r protoc3/bin/* /usr/local/bin/
sudo cp -r protoc3/include/* /usr/local/include/
sudo chown robert_sahlin /usr/local/bin/protoc
sudo chown -R robert_sahlin /usr/local/include/google
# Use this one for recursive generation of java classes
protoc -I/usr/local/include -I=./proto --java_out=./src/main/java/ $(find proto -iname "*.proto")
# Use this one for recursive generation of a descriptor file named schemas.desc
protoc -I/usr/local/include -I=./proto --descriptor_set_out=schemas.desc --include_imports $(find proto -iname "*.proto")
I’ve also packaged it as a docker image that I’ve published on dockerhub that you can use in cloud build to generate your descriptor file and upload it to cloud storage. But that will be covered in a later part in how to automate all steps with google cloud build.